model级
model.eval()与model.train():
eval会停止batch normalization和drop out
tensor级
unsqueeze与 squeeze
tensor.unsqueeze(x)会在该tensor的指定第x维前(x从0开始计)再加一维
如t.unsqueeze(1)会将shape[2, 3]变为shape[2, 1, 3]
tensor.squeeze(x)会在该tensor的指定第x维删除,前提是第x维是1维,如shape[2, 1, 3]只能对第1维进行squeeze变成shape[2,3],否则都不会有任何改变
view
tensor.view(shape)会将tensor的内容填充到指定shape的tensor里, inplace = False
1 | x = torch.rand(2, 2) |
后缀为单下划线_的方法一般指inplace = True的方法,例如
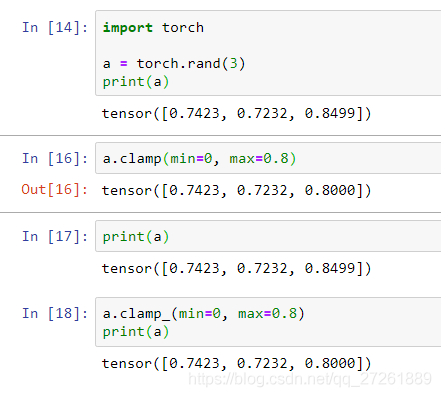
clamp 和 clamp_ :
往torch.tensor()里默认塞的是torch.Size
关于计算图
这个写的很好:一文解释PyTorch求导相关 (backward, autograd.grad)
- non-leaf node指的是计算图的中间变量,需要用gard_fn记录他们的计算来源函数,但是不需要保留他们的grad(
retain_grad = False) - leaf node指的是计算图边缘的叶子结点,是纯粹由用户创建的,默认需要保留他们的grad(
retain_grad = True),需不需要grad可以由用户来决定 - 如果用户创建的结点requires_grad = False,那么该变量在没有non leaf node参与计算时,计算出的变量都是leaf node,如果requires_grad = True,那么普通的数值计算出的变量都是non leaf node
- non-leaf node的grad在bp后不会被保留,需要设置tensor.retain_grad()才行
- clone出来的变量保留了原始变量的requires_grad属性,但仍为non-leaf node,需要手动retain_grad()才能查看其grad
- detach出来的变量从计算图中分离,无法求导
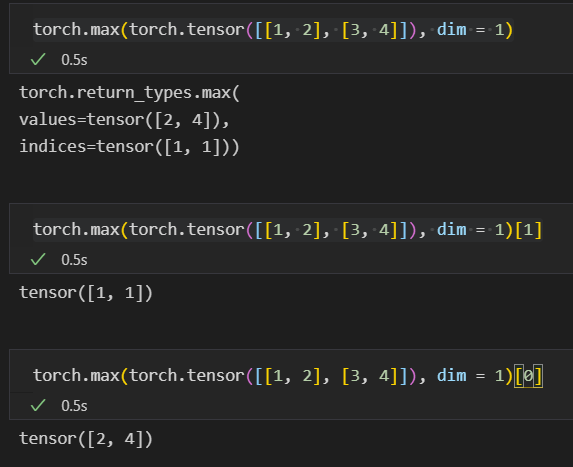
- torch.max()返回的第一项是value,第二项是indice(坐标)
这个打钱就像赞一样,如果你想赞,可以赞一分


- Post link: https://flyleeee.github.io/2021/09/19/pytorch-notebook/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.