李宏毅视频课:https://www.bilibili.com/video/BV1Wv411h7kN?p=16
Exponential Moving Average (EMA)
EMA即指数滑动平均,如下公式所示: 。在你的机器学习项目中用上EMA,可能会有意想不到的效果。实际上,EMA可以看作是Temporal Ensembling,在模型学习过程中融合更多的历史状态,从而达到更好的优化效果。
SGDM
当一个时间窗口内大部分梯度方向大体一致,说明沿着这个方向走是比较置信的,动量项在这种情况下起到加速作用;相反的如果梯度比较随机,则起到缓速作用。从当前梯度和历史梯度方向是否一致的角度出发也有类似的结论。
AdaGrad
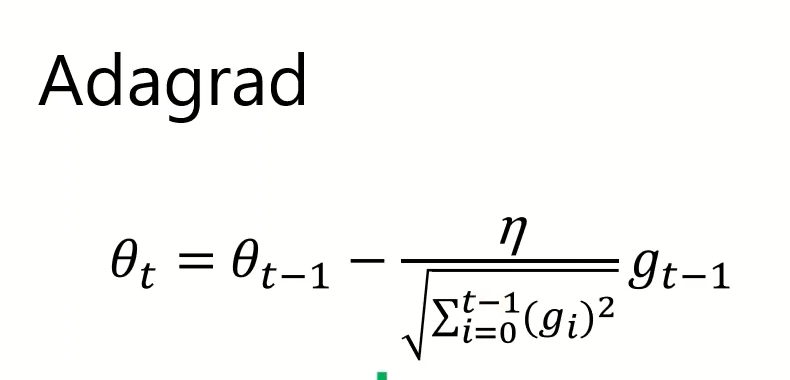
将每次的梯度叠加值除以一个之前梯度的累积,可以防止前期的梯度过大导致在最优点附近步长过大,但这是基于凸优化提出的,实际对于神经网络来说会导致梯度过早和过量的减小
RMSProp
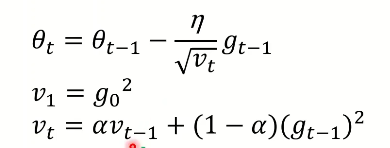
对AdaGrad在非凸情况下做出了优化,对于非凸函数训练神经网络,学习轨迹可能穿过了很多不同的结构,但AdaGrad统计了太多之前别的局部凸函数结构的信息,这是不应该的,RMSRrop使得学习率能更注重于局部凸函数结构。
Adam

Adam主要对于momentum和velocity的累积做出了时间上的平均,在前期可以使这两项不会太小,而在后期使它们不会太大。
比较
Adam与SGDM是近几年SOTA模型都在用的两种优化方法,Adam在test上表现最好,SGDM在validation上的表现最好
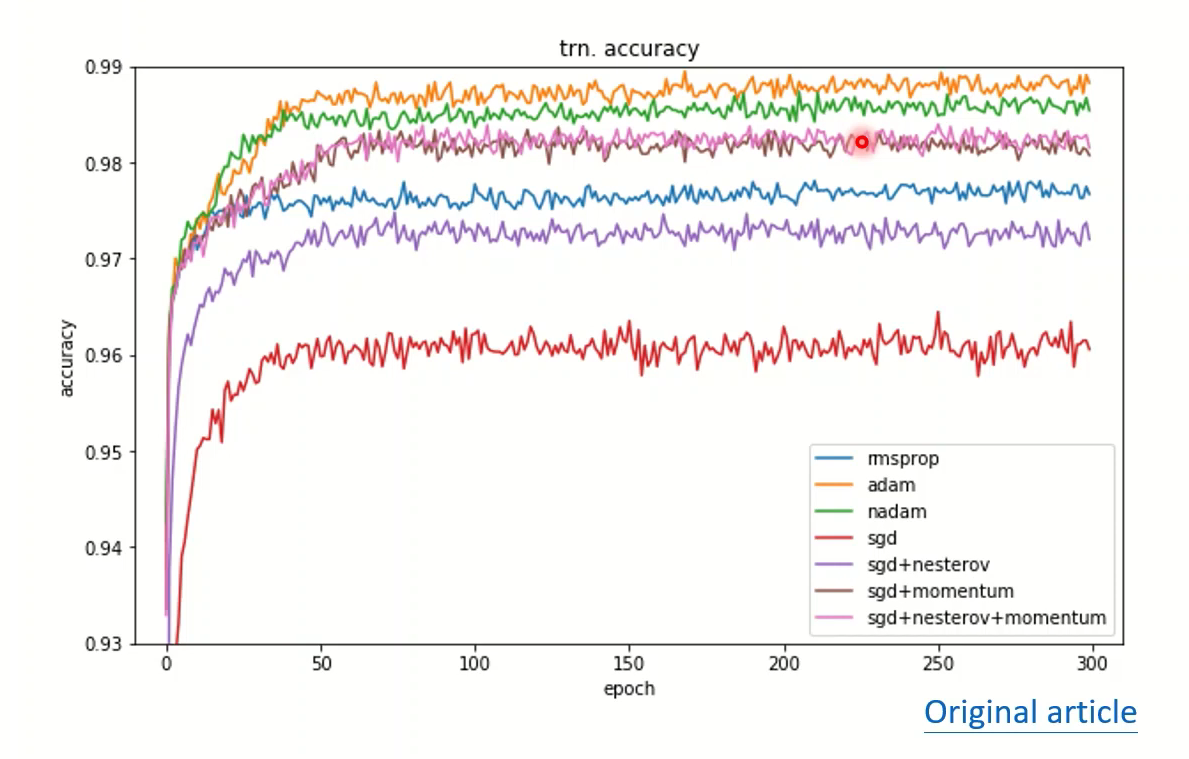
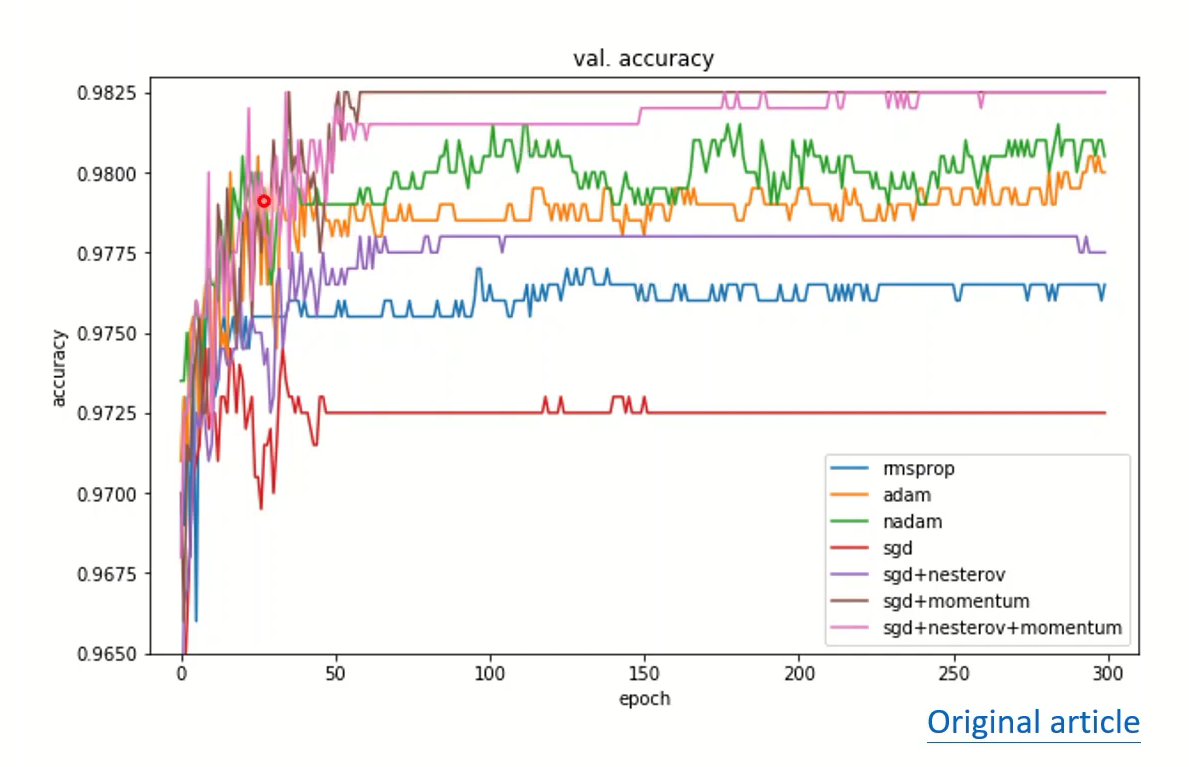
在其他的实验中,Adam一开始训练速度很快,但泛化很差,不稳定;SGDM虽然训练比较慢,但泛化要更好,而且表现稳定
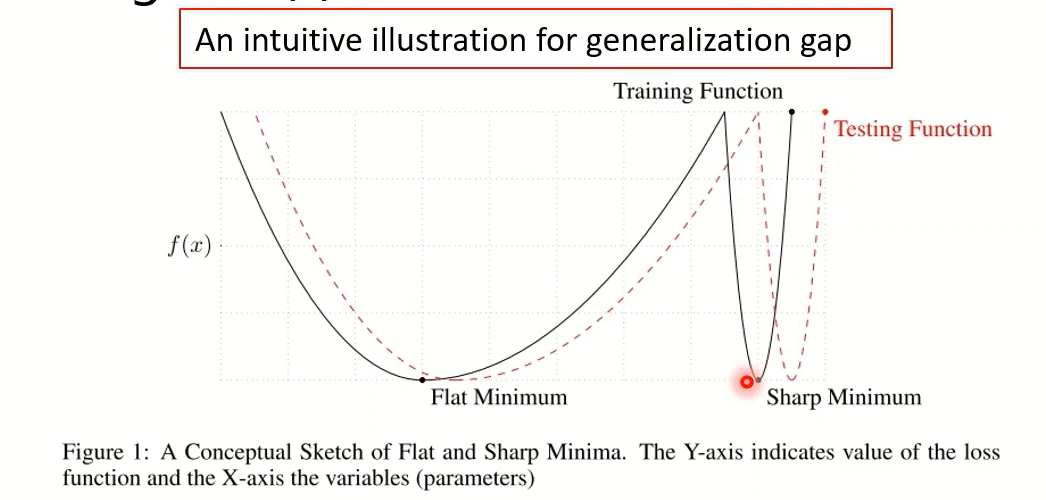
一个直觉的解释:可能是因为Adam找到的是比较sharp的minimum,这种minimum泛化gap会比较大,而SGDM找到的是比较flat的,泛化gap小
SWATS
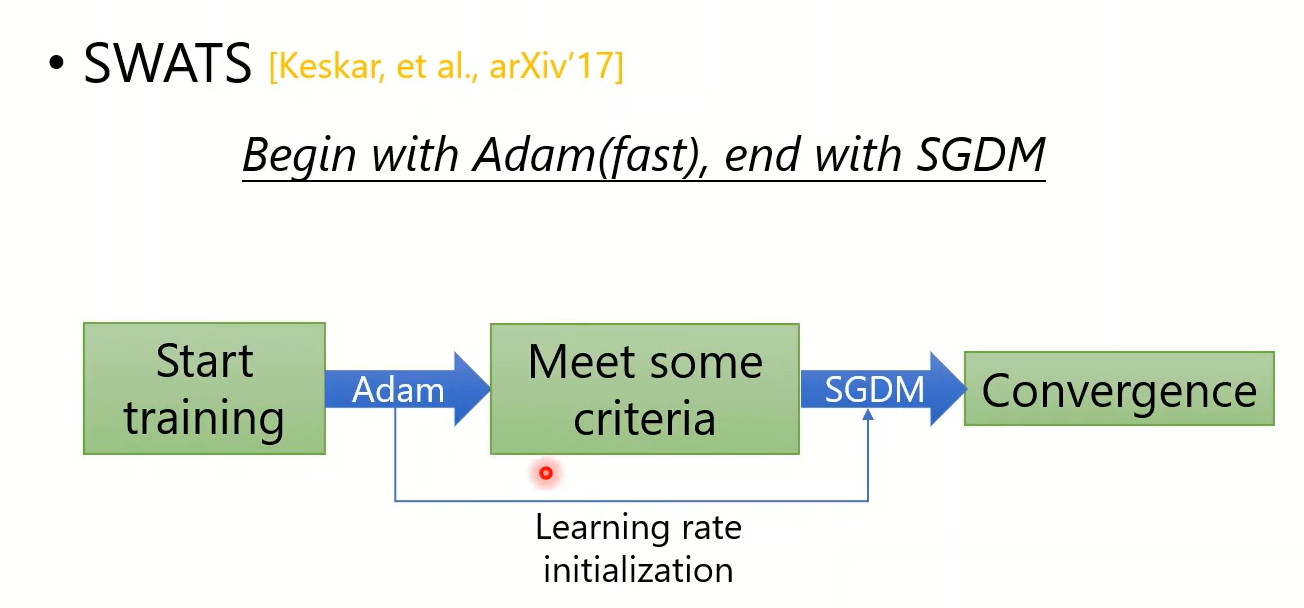
还有好多针对Adam和SGDM的改进方法,但是效果都比较一般,详见视频课
Adam的warm-up
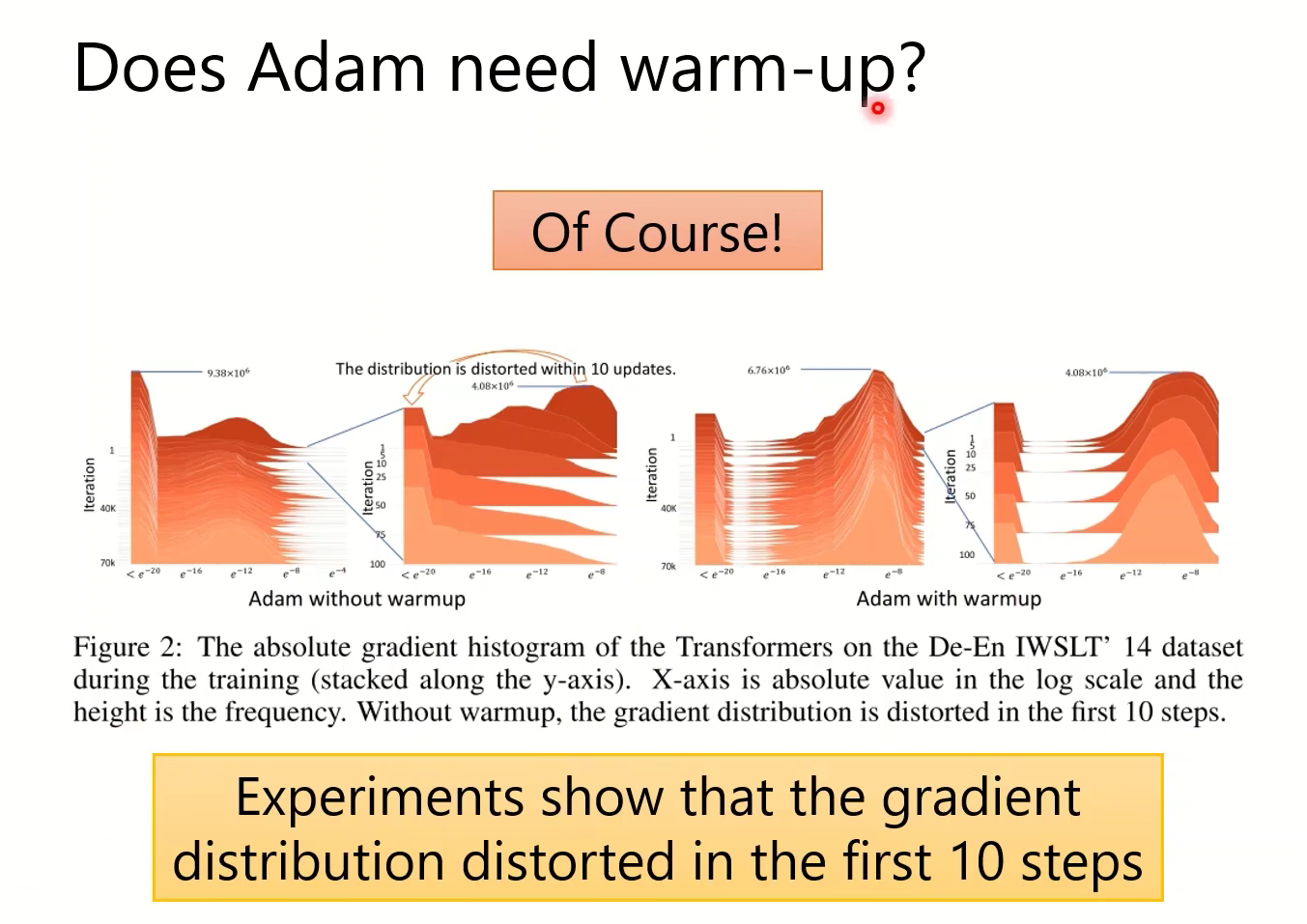
实验表明梯度分布在前10个step会很波动,这让Adam的

RAdam用


- Post link: https://flyleeee.github.io/2021/09/24/%E8%87%AA%E9%80%82%E5%BA%94%E5%AD%A6%E4%B9%A0%E7%8E%87%E7%AE%97%E6%B3%95/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.