处理对象:Sequence Labeling
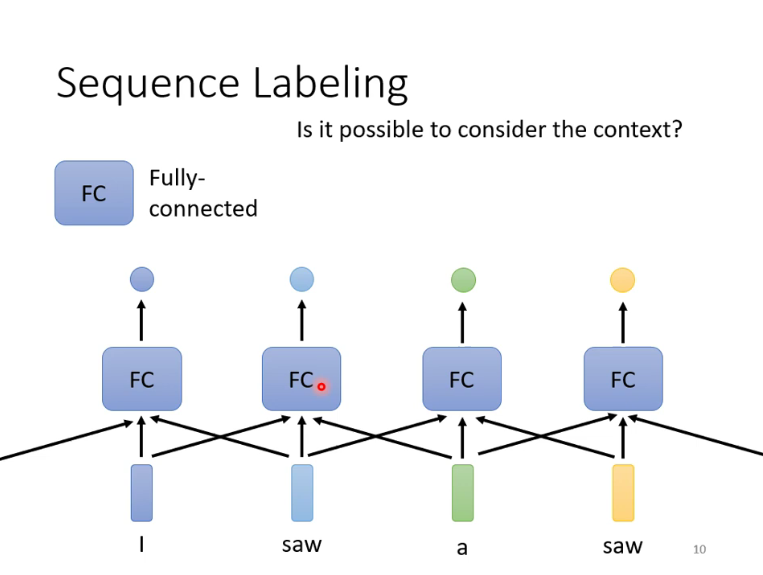
指输入为一系列vector,而输出为每一个vector对应一个label,对于输入vector数量不定的情况,用FCNN明显是不合适的。
简介
self-attention对于每一个输入vector进行处理,使得输出的vector包含了整个context(sequence)的信息。
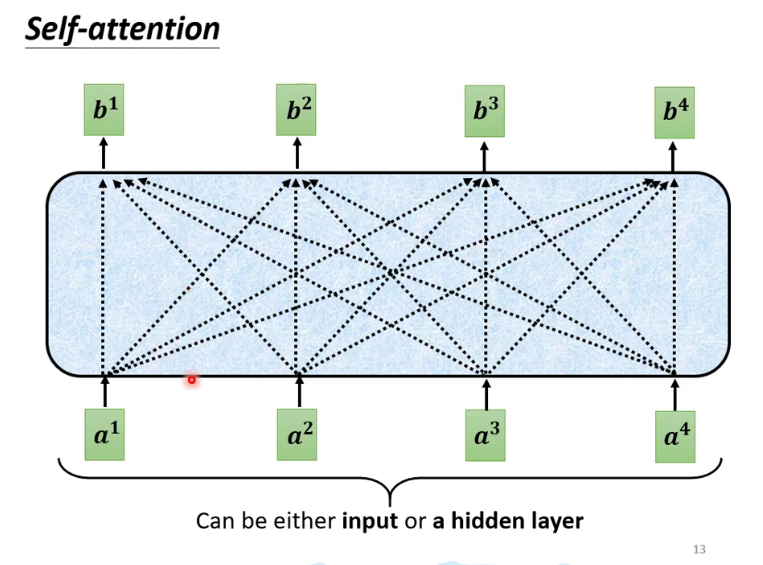
self-attention会计算当前单元与其他输入单元的关联程度
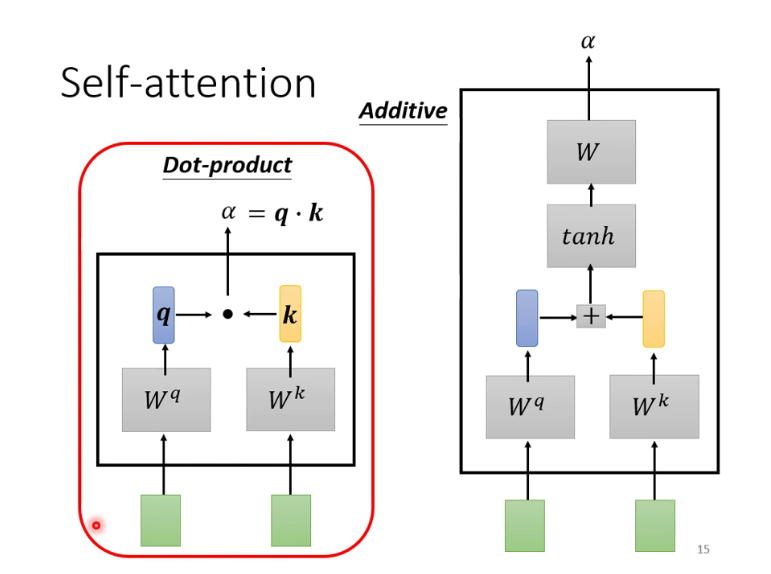
计算
计算
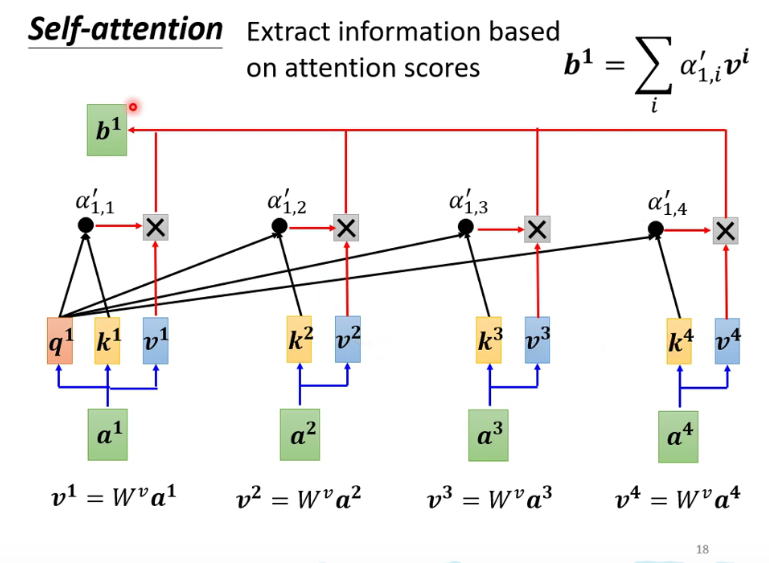
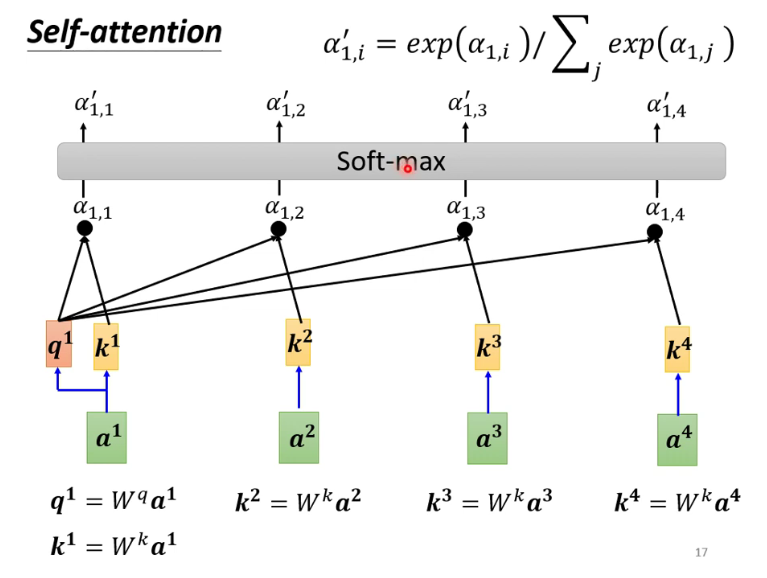
将
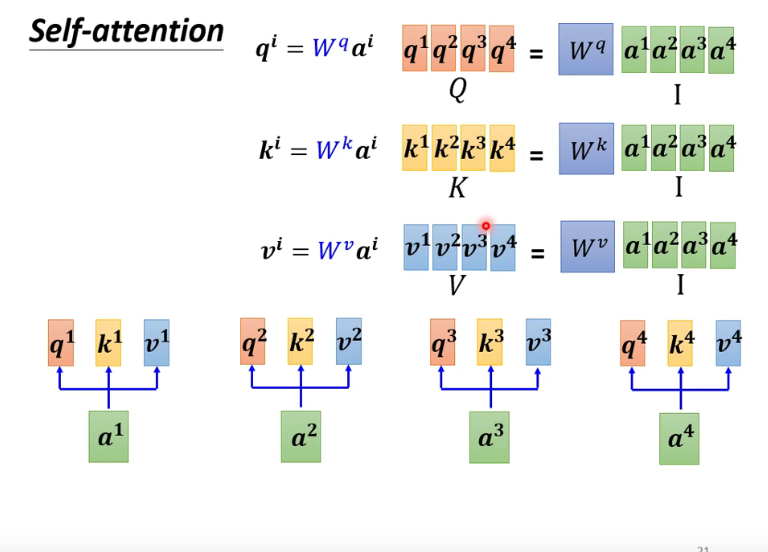
比较关键的是,
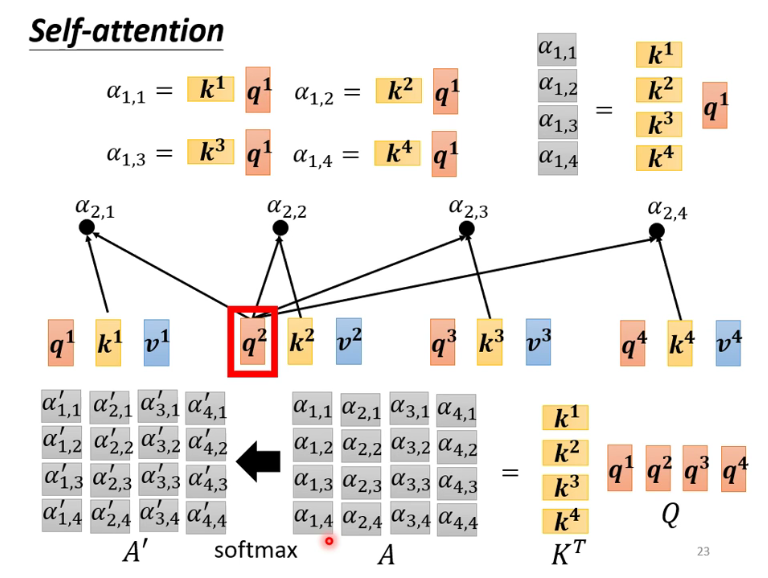
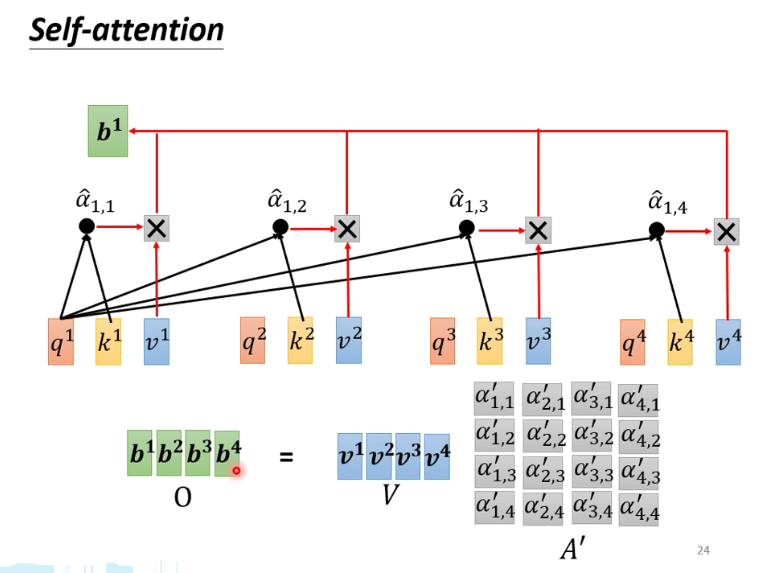
后面的计算过程也可以用矩阵简化,做到并行,不多赘述。
全流程
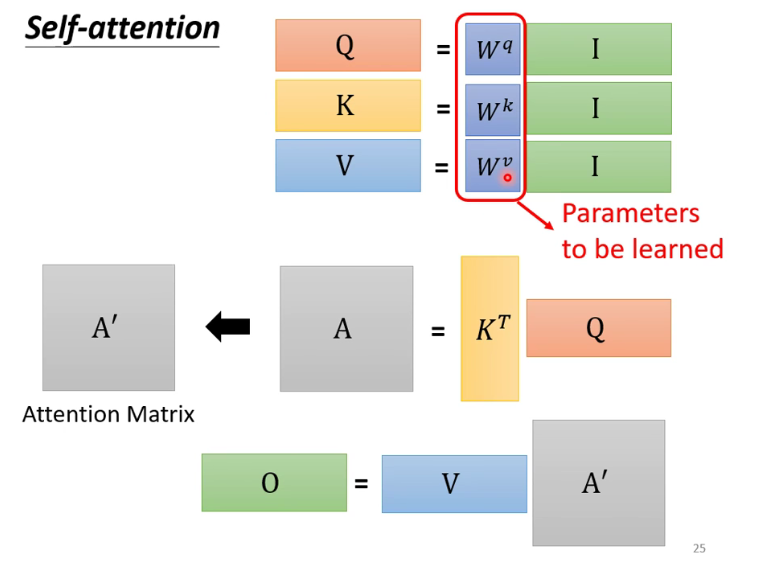
整个过程中,只有
改进
改进1:Multi-head Self-attention
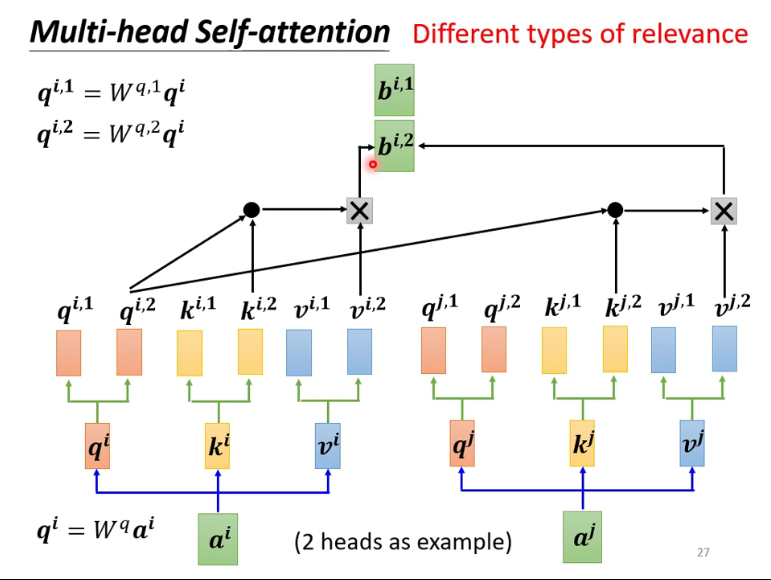

大体上来说就是多算几组,head数需要依据具体问题自己调整,这个方法现在用的比较多
改进2:Positional Encoding
self-attention没有利用相对位置的信息
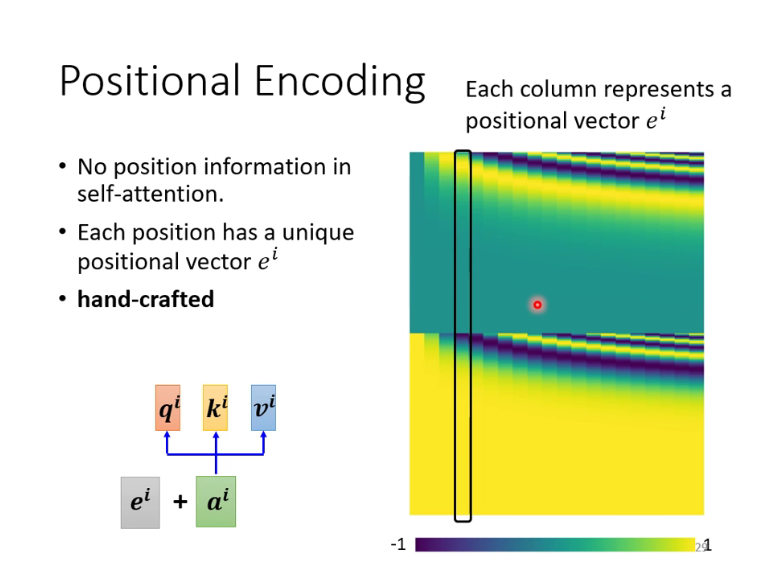
利用一些人工规则为每一个输入向量计算出一个positional vector,这一方面的方法有待研究
Self-attention与CV
在CV上的应用
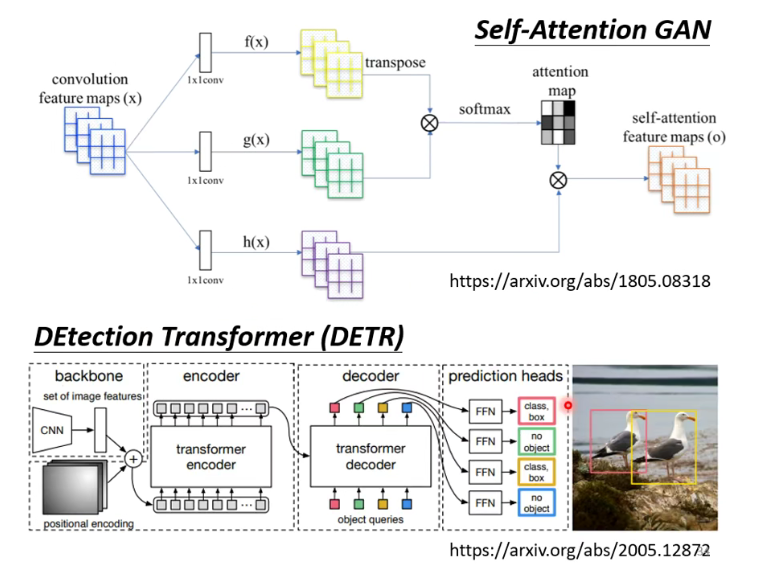
与CNN的关系:CNN就是Self-attention的简化版

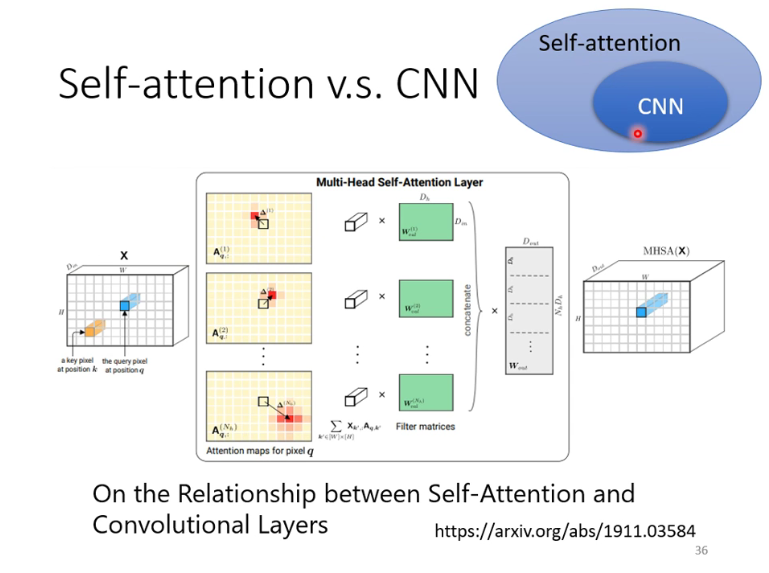
该paper用数学方式证明,CNN就是self-attention的子集,特定参数的self-attention就是CNN
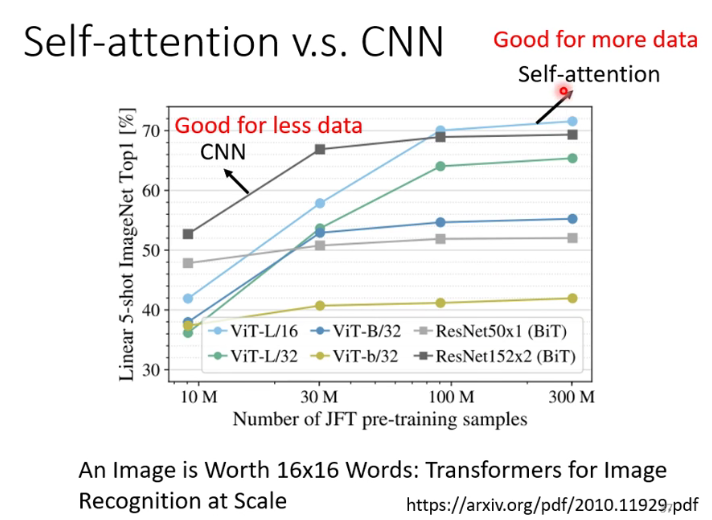
Self-attention弹性大,也需要更多data
对比RNN
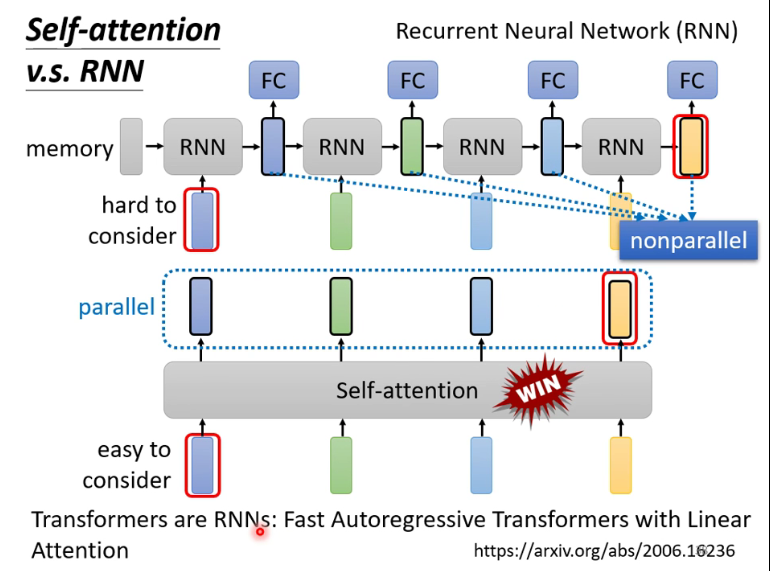
RNN看起来能保留位置信息,但是也有着难以考虑远距离vector的性质,而且无法做到并行处理,因此现在都用Self-attention而不用RNN了,也有一篇paper说明了self-attention加上一些东西就是RNN。


- Post link: https://flyleeee.github.io/2021/10/02/Self-attention/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.