Seq2seq
就是input加到Encoder里,再进Decoder得到output
Encoder
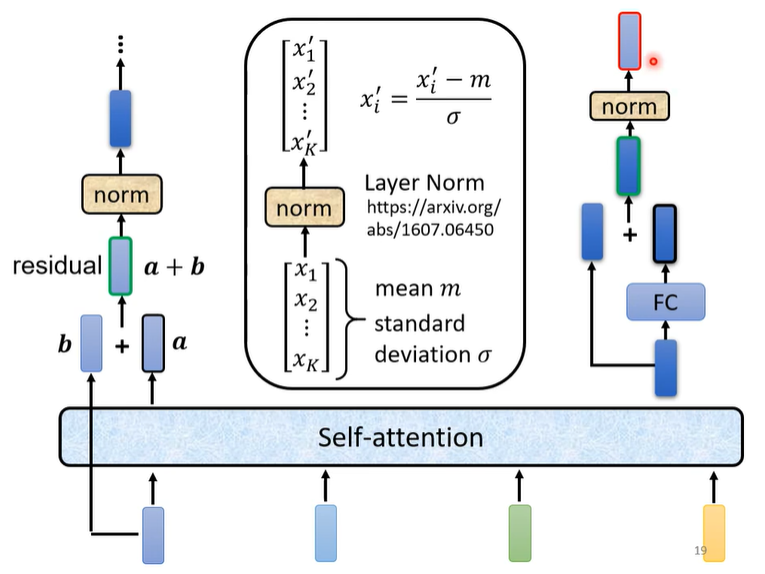
- 这里的Layer norm是对一个输入example的所有dimension做normalization
- 总共两次res,两次norm,对每次res完的加和做norm
实际流程
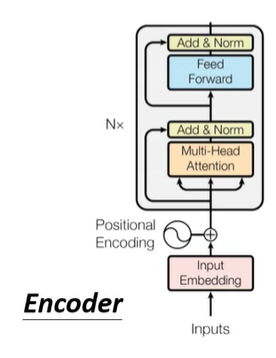
这样的Encoder也用在了BERT里
改进
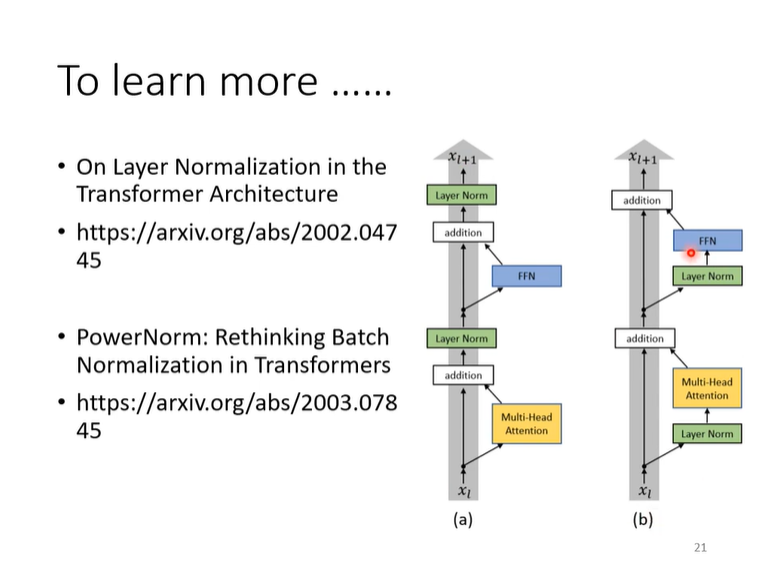
第一篇paper:证明把Layer norm加在res后的主分支里,效果会更好。
第二盘paper:证明了为什么Layer norm在这里要比Batch norm要更好,提出了PowerNorm,好像要更好一点?
Decoder—Autoregressive(AT)
大致流程
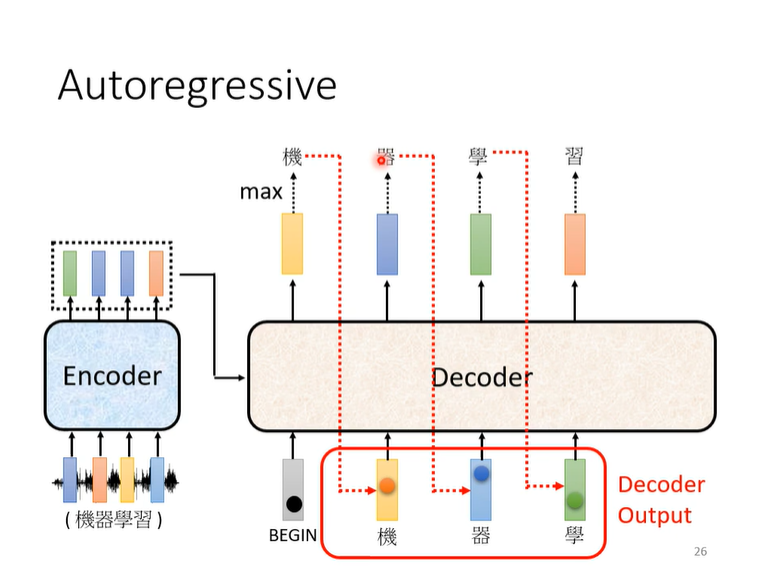
具体流程
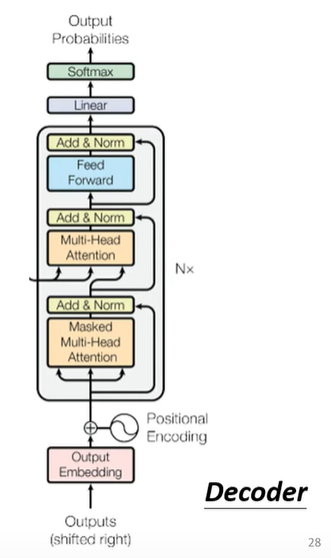
Masked Self-attention
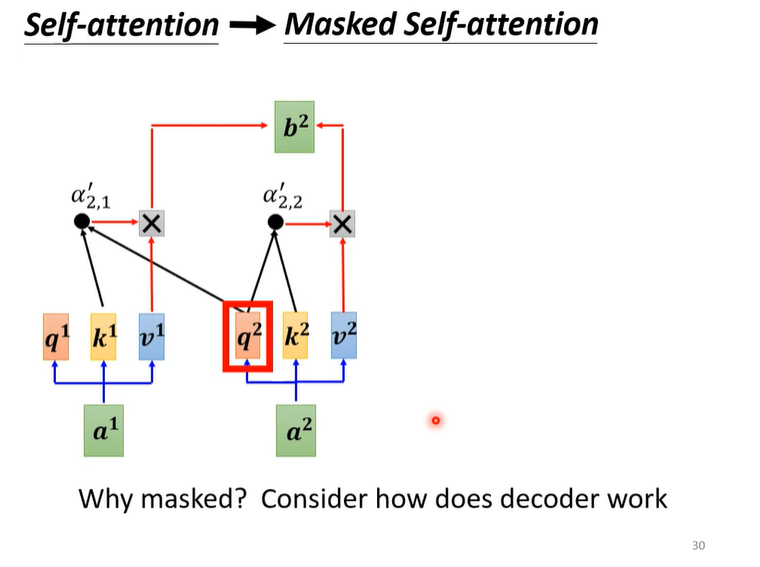
Masked指的是在计算
Decode—Non-autoregressive(NAT)
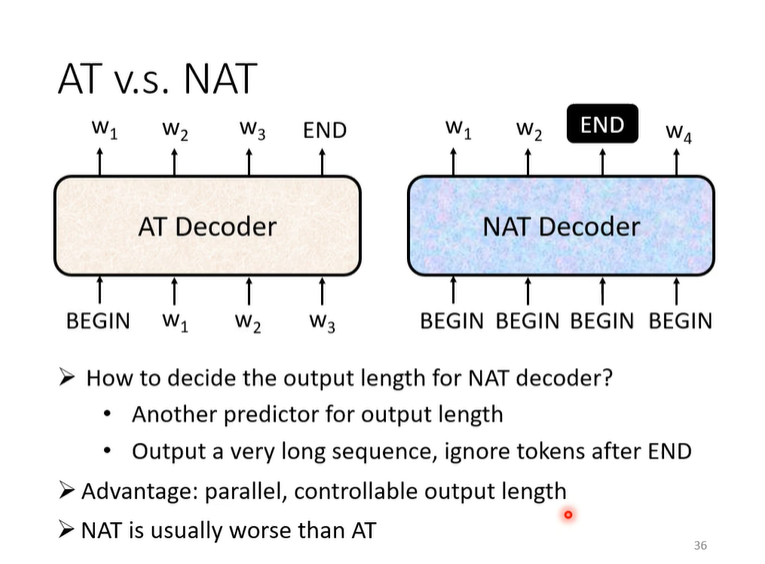
为什么NAT不如AT?因为Multi-modality(详见 To leatn more)
Cross attention
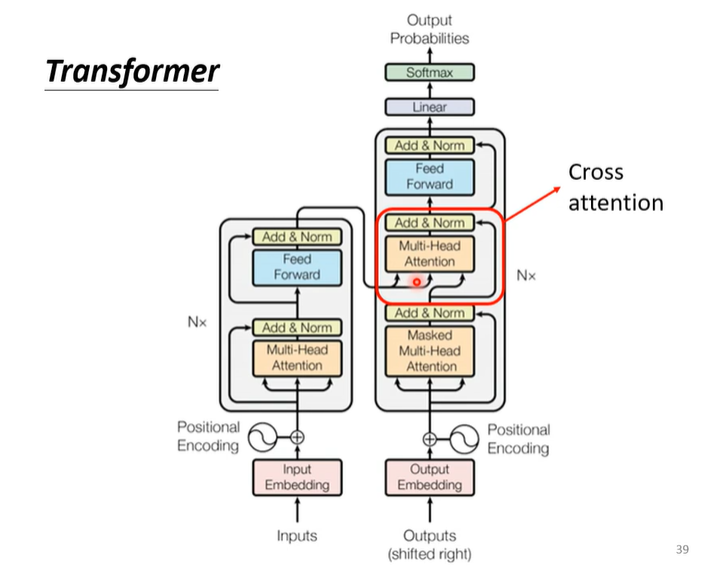
它衔接了Encoder与Decoder
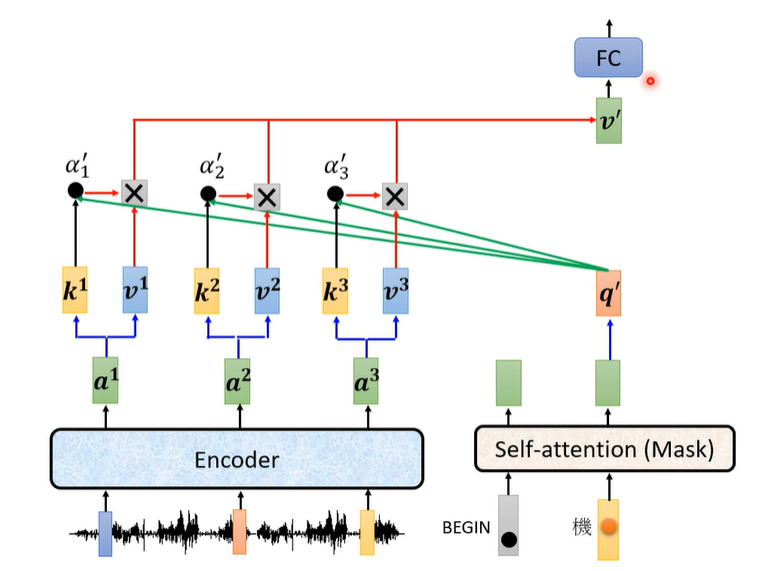
就是把Encoder的输出再拿来,这一次只用当前input的这一个向量
改进
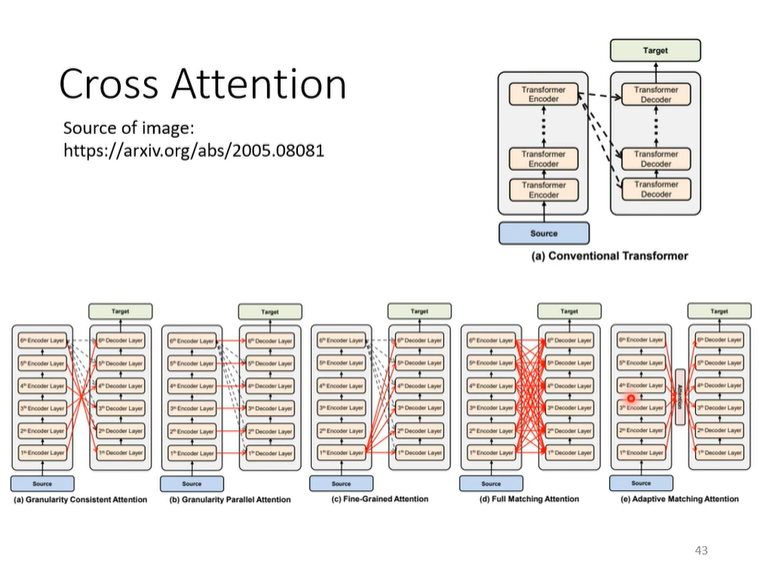
也可以不用Encoder的最后一层的output做Cross Attention
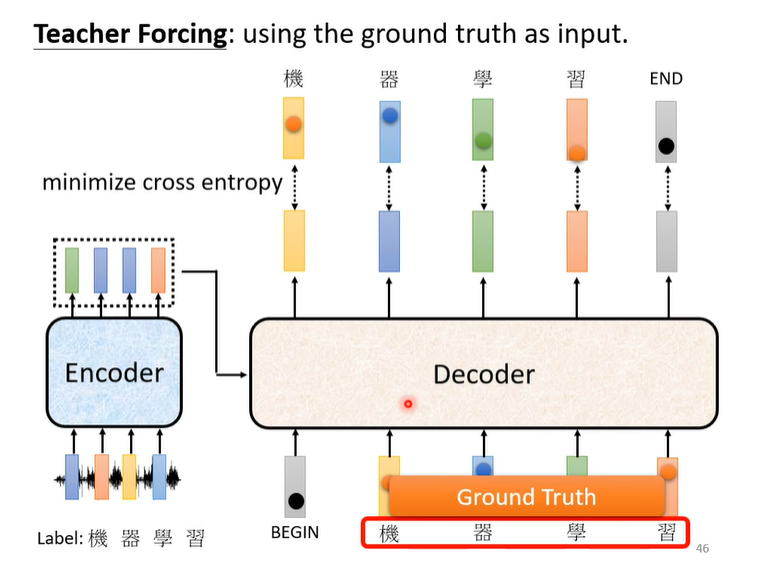
Training
Tips

我们有时候需要机器去做“复述”
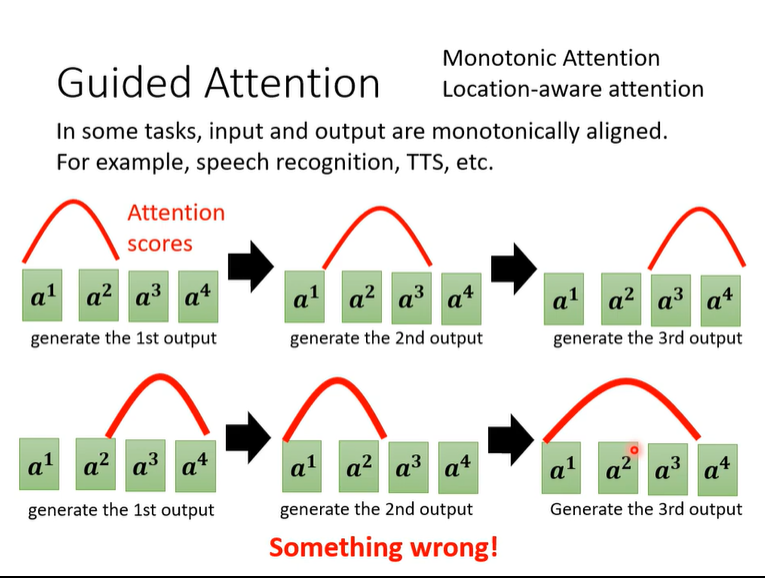
Attention的着重点有时候会出错,可guide它
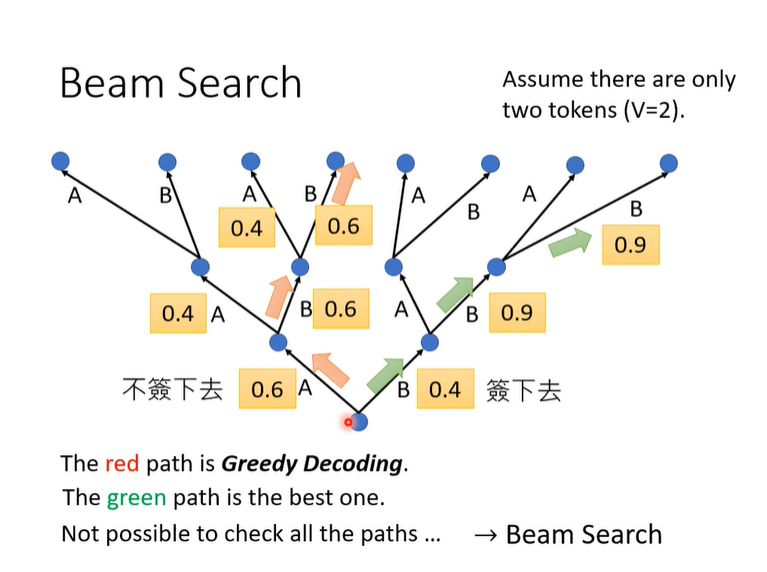
原本的AT是贪心的,可以用柱搜索,做动态规划,但是效果对于实际场景不一,如果问题的正确性比较明确,Beam Search就比较有用,但是有的问题,甚至test的时候都需要一些随机性才能有好的效果
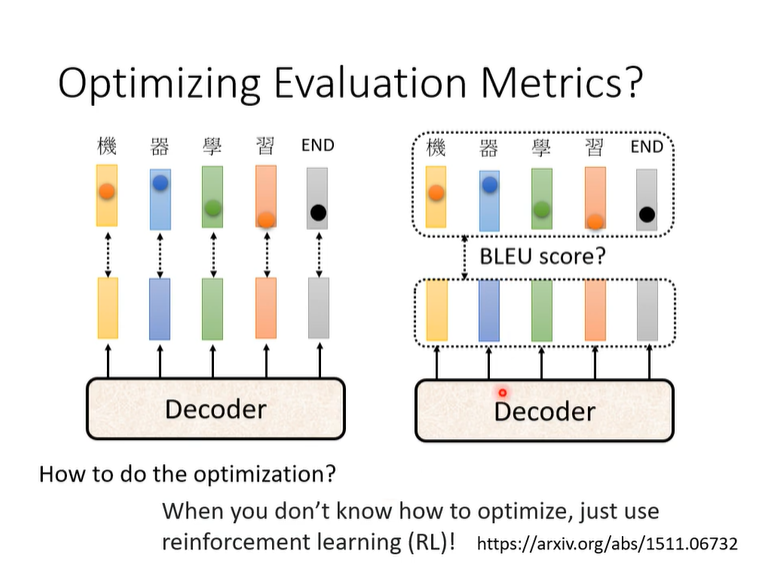
小tip:optim遇到问题的时候可以用RL硬train!
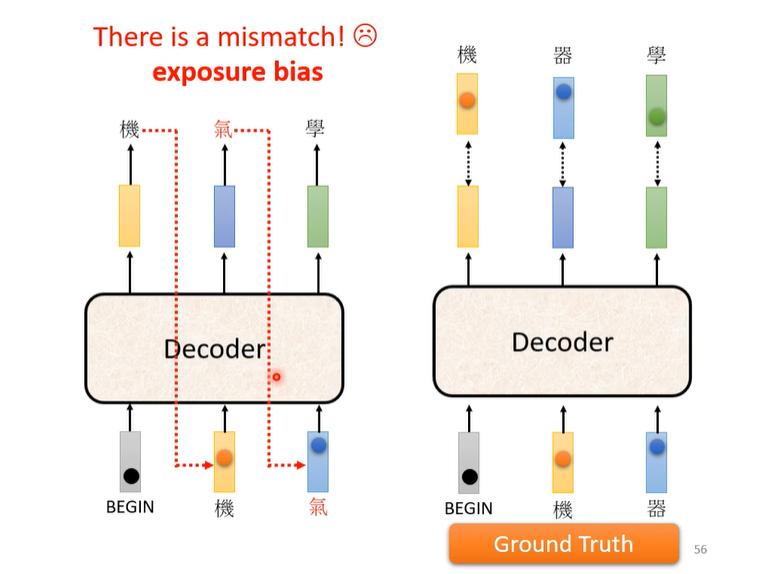
因为train的时候给Decoder的是Ground Truth,为了防止test的时候有wrong propagation,可以在train的时候加noise。
这个打钱就像赞一样,如果你想赞,可以赞一分


- Post link: https://flyleeee.github.io/2021/10/03/Transformer/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.