Towards Certifying
1.Introduction
我们设计出了一种
而由这样的neuron构建的network也具备同样属性。基于这种属性,我们可以通过预测结果的边界有效地得到
理论方面,我们证明了一个Lipschitz-universal近似理论,说明
但是这个网络的参数的梯度的
进一步,
2.Related Work
Robust Training Approaches
对抗训练是对于对抗攻击最成功的应对方法,但是基于预定义的攻击算法进行评估的,无法保证模型对其他攻击也鲁棒
Certified Robustness for CNN
通过一些凸松弛方法,一层一层地约束可证明的扰动半径,从而提供任何攻击下可证明的鲁棒性。然而这些方法一般复杂、计算昂贵且难以应用于深而大的模型。为了克服这些缺陷, Mirman et al. (2018); Gowal et al. (2018) 提出了 interval bound propagation (IBP),一种更简单且易于计算的特殊形式的凸松弛,但也放松了结果的边界,导致了不稳定的训练。Zhang et al. (2020b); Xu et al. (2020a)将IBP与线性松弛结合,使得边界变紧,达到了现在的SOTA表现。与这些为了确定CNN的方法不同,我们提出了一种通过其本质属性就可提供鲁棒性保证的网络。
Certified Robustness for Smoothed Classifiers
Randomized smoothing为常规网络提供了一种基于概率的可证明鲁棒保证。如果给输入加上一个高斯噪声,可以为高斯光滑分类器计算出一个可验证的小的
Lipschitz Networks
另一条路线尝试约束神经网络的全局Lipschitz常数。Lipschitz网络对于证明鲁棒性,提供泛化边界或者估计Wasserstein距离是非常有用的。先前的工作通过直接约束每一个权重矩阵的spectral norm小于1,或者是优化损失函数,构建被spectral norm约束的全局Lipschitz常数上界,来训练Lipschitz ReLU网络。但Huster et al. (2018) and Anil et al. (2019)指出这样的网络对于一些简单的Lipschitz函数欠缺表达能力,而且其Lipschitz约束也不紧。最近, Anil et al. (2019)提出了一个新的Lipschitz网络: Lipschitz-universal approximator,(Li et al., 2019)将其拓展到了CNN上。然而其鲁棒性仍不及其他可证明的方法,并且它们都不能提供
我们注意到有人提出了一种叫做AdderNet的新网络,利用
3.
3.1 Preliminaries
Consider a standard classification task. Suppose we have an underlying data distribution
以
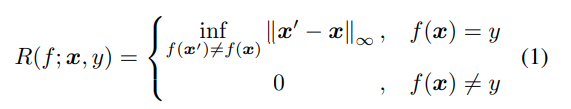
但是计算一个标准DNN的 robust radius 是很难的,已经证明了计算ReLU的DNN的这种半径是NP-hard问题。于是研究者开始寻求对于常规
3.2 Networks with
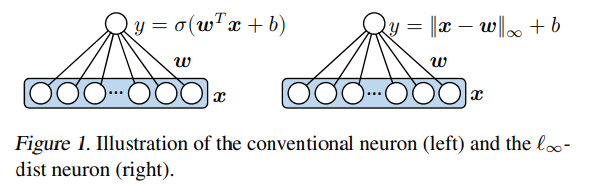
where
因为它计算了
Remark 3.1.
传统网络用点乘来表示
对于分类任务,我们使用最后一层layer的负数$g(x)=(-x^{(L)}1, -x^{(L)}_2,…, -x^{(L)}_M)
3.3 Lipschitz and Robustness Facts about
通过简单直接的证明,说明了这样的
Fact 3.6.
定义
即
因此,我们仅需一次前传即可确定任意大小
鲁棒性,而不像现有的其他确定方法会受到poor scalability(基于线性松弛的方法)或者维数curse(randomized smoothing)的影响
4. Theoretical Properties of
一个模型的表达能力和泛化性是ml中最重要的。我们将证明
4.1 Lipschitz-Universal Approximation of
对于任意
而这样的函数
4.2 Bounding Robust Test Error of
分类器
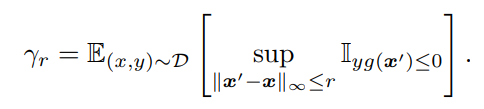
那么

理论4.2说明了当在训练集中得到一个大边界(large margin)的分类器,并且网络size不是太大时,我们模型有很大概率可以在对抗鲁棒性上得到好的泛化,而且我们这一泛化边界不会像普通的Lipschitz模型一样受到输入维度的影响。
5. Training
基于先前的理论,我们想做到的是在训练集中达成一个大边界的解,于是我们使用了标准的多分类的hinge loss,因为该 loss 几乎处处可微,所以可以使用任何基于梯度的优化方法。
但是我们发现实际上优化很难做,像batch-normalization这样的传统方法会伤害网络的鲁棒性,接下来分析优化困难处,并提出一系列优化策略。
5.1 Normalization
normalization是将layer输出范围控制住的有效方法,batch-normalization使用shift和scale操作特征值,是训练DNN的重要组件,但是batch-normalization在
不过我们发现只使用shift操作就能帮助优化,因此我们在所有的中间层计算完
5.2 Smoothed Approximated Gradients
于是我们在整个网络上使用
5.3 Parameter Initialization
我们发现深层模型的 training accuracy 表现劣于浅层模型,Kaiming提出ResNet,用 identity mapping 解决了这一问题。根据附录A的命题A.2,有着初始化恰当的weights和biases的
具体来说,对于一个有着相同输入-输出维度的
5.4 Weight Decay
权重衰减会劣化
传统网络使用点乘,权重上加以
在
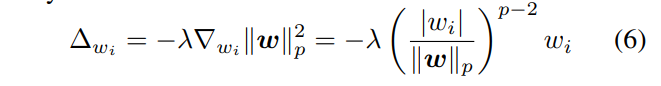
当p趋于无穷,权重衰减倾向于只对绝对值最大的
6. Certified Robustness by Using
当我们只在特定的流形(例如真实图像流形)需要Lipschitz性时,
因为
After obtaining the bound, we can set it as the training objective function to train the neural network parameters, similar to Gowal et al. (2018); Zhang et al. (2020b).这段没看懂
7. Experiments & Results
对比
用同样超参跑8次的平均值
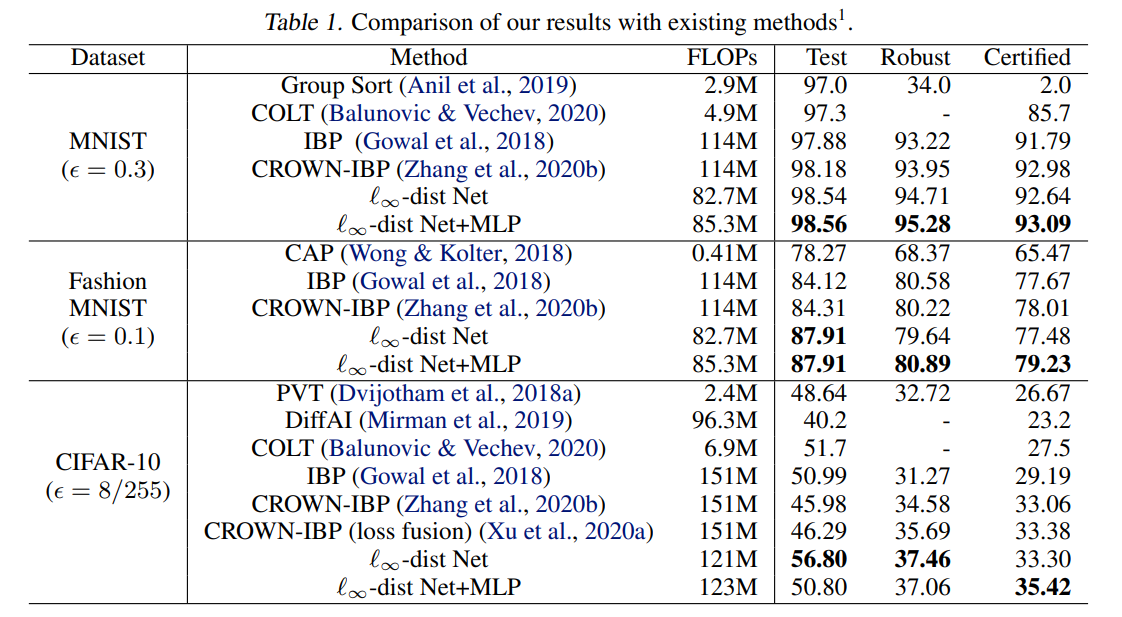
模型细节

As for the loss function, we use multi-class hinge loss for ∞-dist Net and the IBP loss (Gowal et al., 2018) for ∞-dist Net+MLP
比较有意思的是把



- Post link: https://flyleeee.github.io/2021/12/03/l-infty-net/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.