Towards Deep Learning Models Resistant to Adversarial Attacks
对于每个数据点x,我们引入了一组允许的扰动,这些扰动形式化了对抗的操纵能力。对于图像分类,我们挑选出能捕获图片间知觉相似性的扰动。the L∞-ball around x 最近被研究认为是对抗扰动的自然概念。更全面的知觉相似性概念是未来研究的一个重要方向。
我们修改了优化目标,允许对抗首先去干扰输入
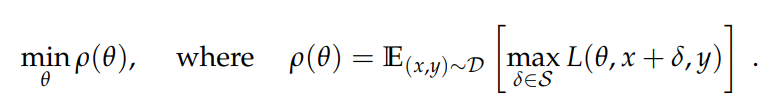
将鞍点问题视为内部最大化问题(非凹)(找到达到高loss的对抗样本)和外部最小化问题(非凸)(找到使内部攻击产生的对抗损失最小的模型参数)的组合,这一目标保证了模型的鲁棒性,关键就在于如何达成这一目标
Towards Universally Robust Networks
我们的主要贡献之一是展示在实践中,人们毕竟还是可以解决鞍点问题。该问题的loss landscape有着local maxima的可处理结构,这一结构也指出PGD是终极的一阶对抗
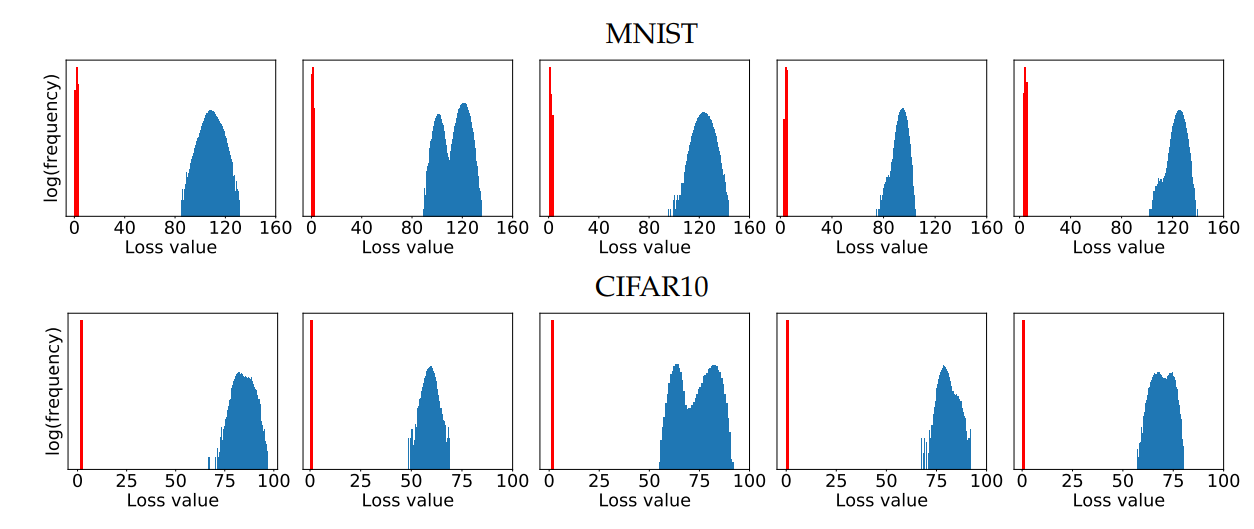
实验说明不同local maxima下的对抗样本有着接近的loss值,这也说明了PGD是universal的一阶对抗,而能够防御PGD的鲁棒性也能防御所有的一阶对抗
Danskin's theorem指出:
对内层最大值求梯度,确实就是求解梯度的下降方向。
所以使用内层生成的对抗样本去训练网络,就是有效的
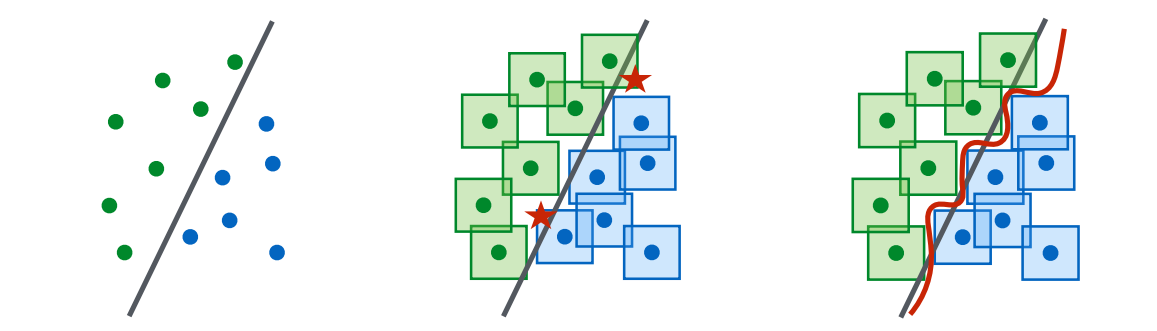
上图说明了鲁棒性高的模型应该是很复杂的,架构容量必须很大,所以要做到
训练一个模型容量足够大的网络;
使用最强攻击方法(
PGD去训练)。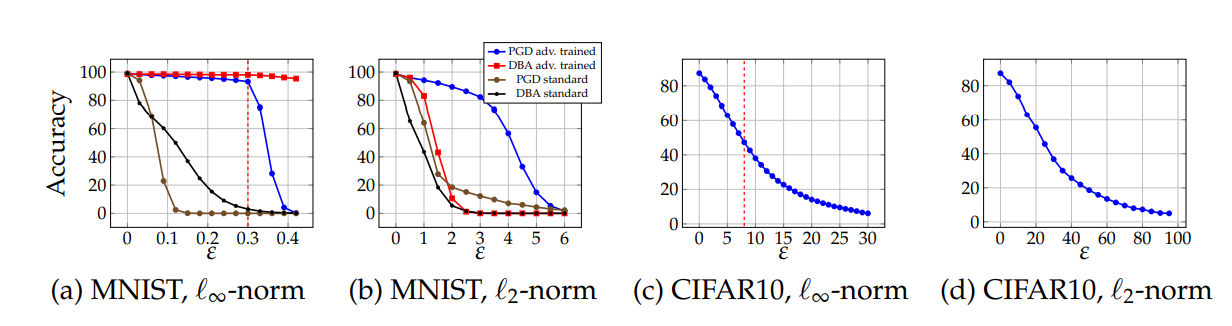
实验还发现
此外,对于 MNIST的攻击,发现PGD方法,即使使用较大的 PGD在overestimating的性质)。这可能是因为学习到的网络将梯度信息隐藏了,这样PGD方法不再那么有效。若使用decision-based的方法进行攻击,则模型表现的较


- Post link: https://flyleeee.github.io/2021/12/04/adv-training/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.