这篇文章是
首先作者定义了r-离散的概念,并证明了

表为


改进
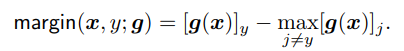
之前使用的hinge loss
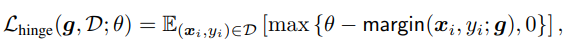
把
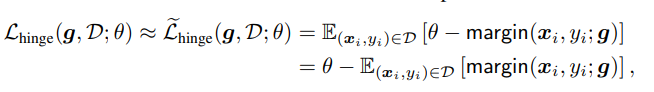
但是因为绝大多数样本的输出margin都是小于
然后在net v1中这个
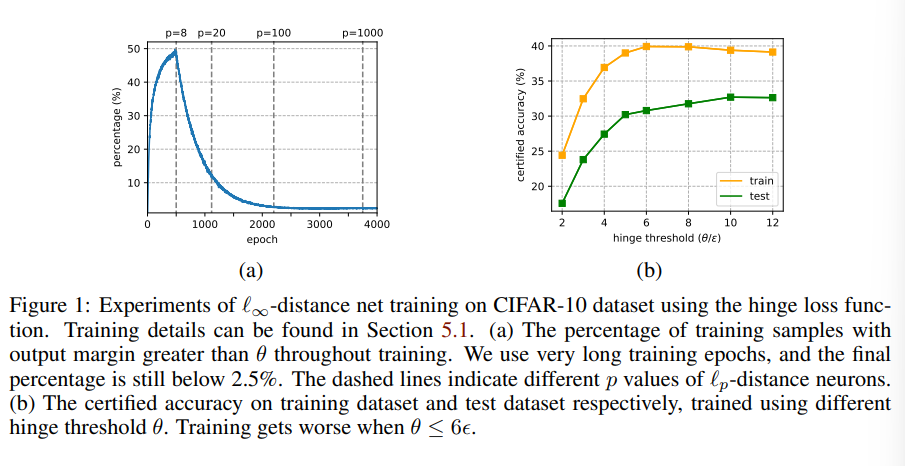
这是因为早期训练取的norm p的p很小,导致利普希兹常数很大
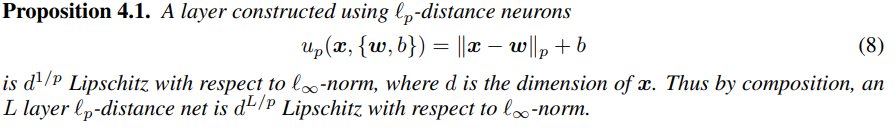
使得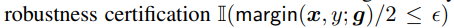 失效,导致数据点的margin满足条件时,实际上也很靠近决策边界,这样hinge loss在早期训练就陷入了错误解,而后期p大了,梯度就已经离散,无法使得参数回到正确解
失效,导致数据点的margin满足条件时,实际上也很靠近决策边界,这样hinge loss在早期训练就陷入了错误解,而后期p大了,梯度就已经离散,无法使得参数回到正确解
For small θ, the margin optimization becomes insufficient at early training stages when the Lipschitz constant is exponentially large, leading to worse performance even on the training dataset.
解决方法
为了训练网络,
cross-entropy也能扩大正确类和错误类的logit距离,但是很粗糙,当模型逼近1-Lipschitz时,hinge loss仍然比cross entropy要好,可以说他们是互补的
所以我们将其缝合在了一起:
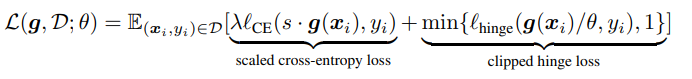
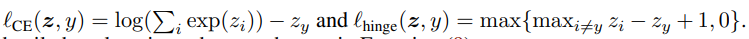
Scaled cross-entropy loss
它处理p很小时的优化问题。我们知道交叉熵是对shift操作不变的(对每一个logit加一个常数),但对scaling操作不是。
但是
Clipped hinge loss
它是为了使p接近无穷时获得鲁棒性,与传统hinge loss不同之处在于,clipped版本loss在分类错误时是稳定的(值为1)
原因是(1)scaled cross entropy已经让模型注意于获得高的clean acc,因此不必再重复用hinge loss去优化,而且cross entorpy在分类优化上比hinge loss好
(2)在晚期训练阶段,优化很困难,错误的分类样本可能几乎不可能变得鲁棒,于是clipped hinge loss忽略了它们,集中注意力去优化更好训练的样本(正确分类的)
(3)它是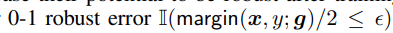 的更好替代,由于cross entropy的存在,hinge threshold可以设为更小的值,避免了loss退化现象
的更好替代,由于cross entropy的存在,hinge threshold可以设为更小的值,避免了loss退化现象
混合系数
实验结果
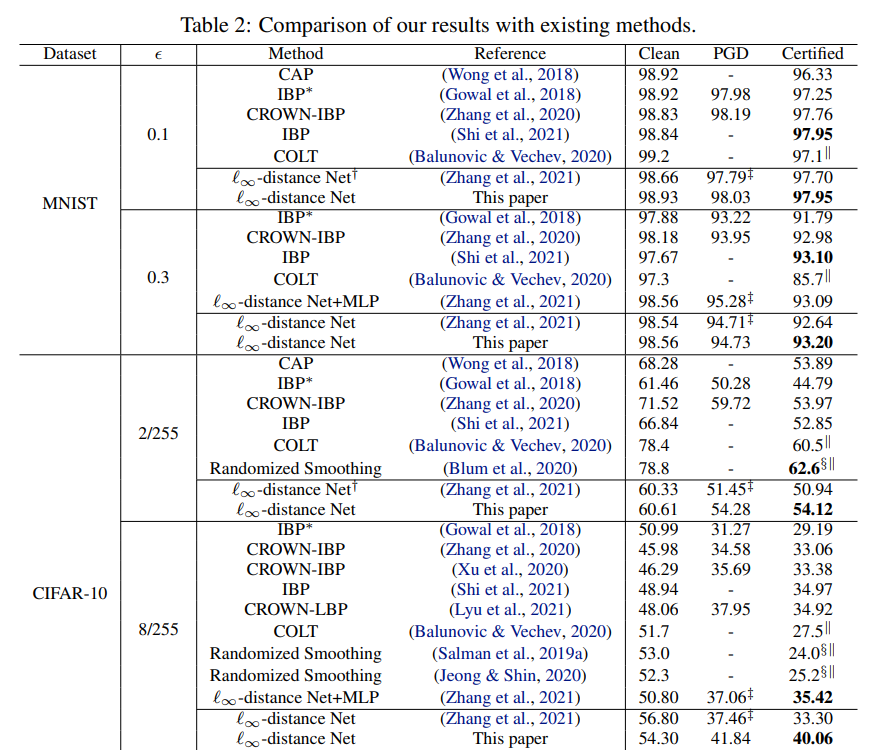
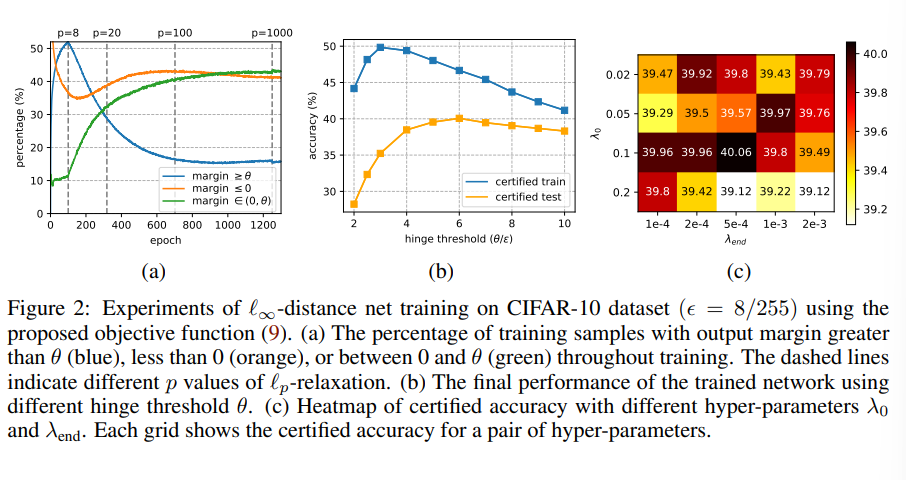
可以看到现在输出margin大于
总结
可做的方面:


- Post link: https://flyleeee.github.io/2021/12/25/l-infty-net-v2/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.